
Data Lake
Introduction
- A data lake is a centralized repository designed to store, process, and secure large amounts of structured, semistructured, and unstructured data.
- It can store data in its native format and process any variety of it, ignoring size limits.
- A data lake provides a scalable and secure platform that allows enterprises to: ingest any data from any system at any speed—even if the data comes from on-premises, cloud, or edgecomputing systems.
- Store any type or volume of data in full fidelity, process data in real time or batch mode.
- Analyze data using SQL, Python, R, or any other language, third-party data, or analytics application.
Purpose of data lake
- Data lakes allow you to store relational data like operational databases and data from line of business applications, and non-relational data like mobile apps, IoT devices, and social media.
- They also give you the ability to understand what data is in the lake through crawling, cataloging, and indexing of data.
Contrasting with Traditional Data Storage Solutions
- Traditional systems mandate that data be cleaned, structured, and organized before being stored. This pre-processing can be time-consuming and often results in a loss of valuable information.
- Furthermore, the structured nature of traditional systems can hinder the storage of unstructured data, which includes text documents, images, videos, and more.
- In contrast, data lakes offer a departure from this structured paradigm.
- They can accommodate data in its raw form, whether it’s generated from social media interactions, IoT devices, or customer reviews.
This flexibility is especially beneficial in an era where data comes in many shapes and sizes and where its value may not be apparent until it’s analyzed in-depth.
Key Components of Data Lakes
- Storage Layer:
- The foundation of a data lake is its storage layer.
- This is where all data is ingested, whether structured or unstructured.
- Common storage solutions include Hadoop Distributed File System (HDFS) and cloud-based storage like OceanStor Dorado All-Flash Storage.
- Ingestion Layer:
- This layer handles the process of ingesting data into the data lake.
- It involves data acquisition, transformation, and loading (ETL) processes.
- Tools like Apache Nifi, Apache Kafka, or cloud-based services facilitate data ingestion.
- Metadata Catalog:
- Metadata is critical for data lake management.
- It provides information about the data, including its source, format, and structure.
- Tools like Apache Atlas or Huawei Cloud Data Catalog help in managing metadata.
- Data Governance and Security:
- Ensuring data governance and security is crucial.
- Access controls, encryption, and auditing mechanisms are put in place to protect sensitive data and comply with regulations like GDPR or HIPAA.
- Data Processing Layer:
- This layer enables data transformation, analysis, and reporting.
- Technologies like Apache Spark, Apache Hive, or cloud-based services are used for data processing.
- Query and Analytics Layer:
- Here, data is made accessible to analysts and data scientists.
- Users can run queries and perform analytics to extract insights from the data.
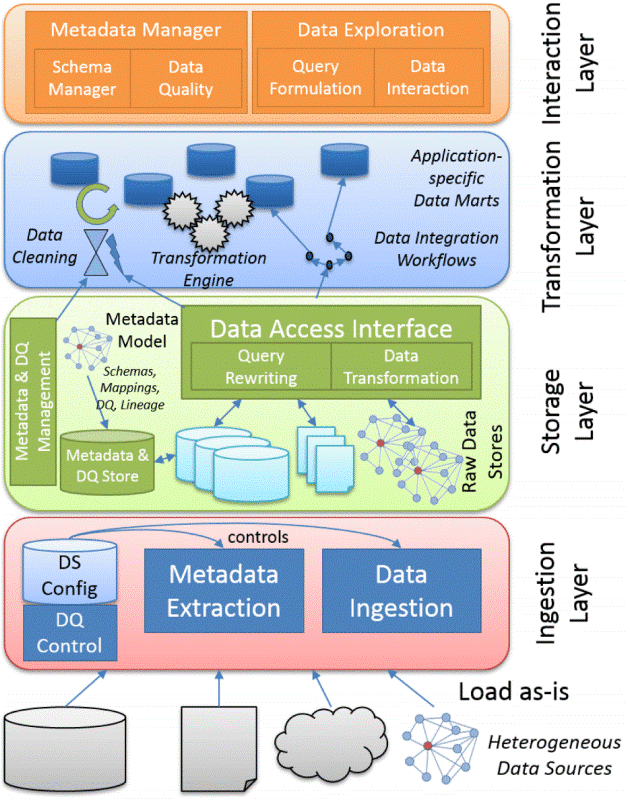
Data lake architecture
- This section will explore data architecture using a data lake as a central repository.
- While we focus on the core components, such as the ingestion, storage, processing, and consumption layers, it’s important to note that modern data stacks can be designed with various architectural choices.
- Both storage and compute resources can reside on-premises, in the cloud, or in a hybrid configuration, offering many design possibilities.
- Understanding these key layers and how they interact will help you tailor an architecture that best suits your organization’s needs.
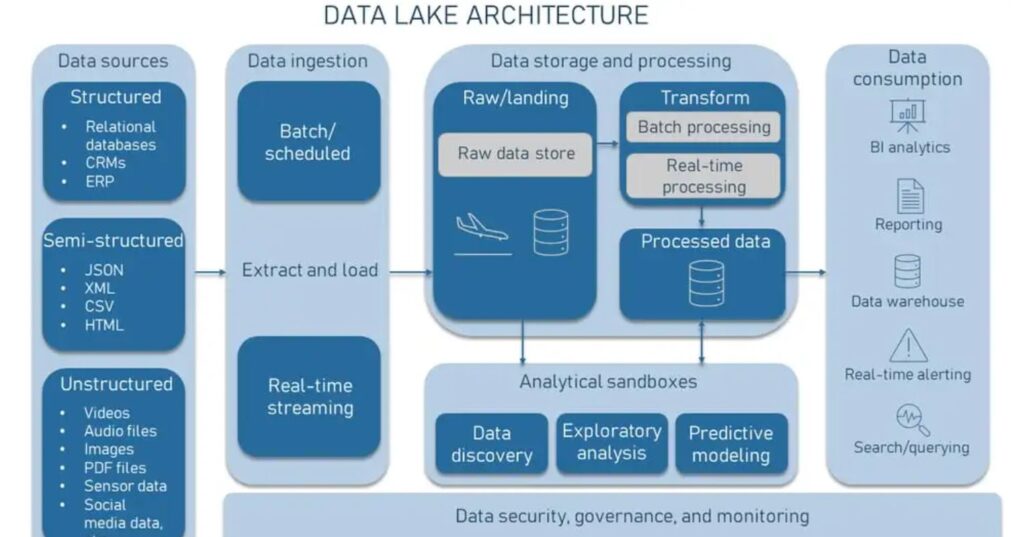
Data lake use cases
With a well-architected solution, the potential for innovation is endless. Here are just a few examples of how organizations across a range of industries use data lake platforms to optimize their growth
Streaming media:
Subscription-based streaming companies collect and process insights on customer behavior, which they may use to improve their recommendation algorithm.
Finance:
- Investment firms use the most up-to-date market data, which is collected and stored in real time, to efficiently manage portfolio risks.
Healthcare:
- Healthcare organizations rely on big data to improve the quality of care for patients. Hospitals use vast amounts of historical data to streamline patient pathways, resulting in better outcomes and reduced cost of care.
IoT:
- Hardware sensors generate enormous amounts of semi-structured to unstructured data on the surrounding physical world. Data lakes provide a central repository for this information to live in for future analysis.
Digital supply chain:
- Data lakes help manufacturers consolidate disparate warehousing data, including EDI systems, XML, and JSONs.
Sales:
- Data scientists and sales engineers often build predictive models to help determine customer behavior and reduce overall churn.
Data lake vs. data warehouse
| Data lake | Data warehouse |
|
Type | Structured, semistructured, unstructured | Structured | |
Relational, nonrelational | Relational | ||
Schema | Schema on read | Schema on write | |
Format | Raw, unfiltered | Processed, vetted | |
Sources | Big data, IoT, social media, streaming data | Application, business, transactional data, batch reporting | |
Scalability | Easy to scale at a low cost | Difficult and expensive to scale | |
Users | Data scientists, data engineers | Data warehouse professionals, business analysts | |
Use cases | Machine learning, predictive analytics, real-time analytics | Core reporting, BI |
Common challenges in data lake implementations
Implementing a data lake comes with its own set of challenges. Here are some common challenges associated with data lake implementations:
Data Quality:
Ensuring data quality and reliability can be challenging, as data lakes often accumulate large volumes of diverse data from various sources.
Metadata Management:
Properly managing and organizing metadata is crucial for effective data governance. Incomplete or inaccurate metadata can lead to confusion and misuse of data.
Data Governance and Security:
Implementing robust data governance practices and ensuring data security can be complex.
Access control, encryption, and compliance with regulations are critical aspects.
Scalability:
As the volume of data grows, scaling the data lake infrastructure while maintaining performance can be a significant challenge.
Integration with Existing Systems:
Integrating the data lake with existing systems and applications can be challenging, especially when dealing with legacy systems that may not be designed to interact with modern data lakes.
Complexity of Querying and Analysis:
Users may face challenges when querying and analyzing data from the data lake, especially if they are not familiar with the underlying data structures or if the data lake is not properly organized.
Cost Management:
Data lakes can incur significant costs, especially when using cloud-based solutions. Managing costs efficiently while ensuring optimal performance is a constant concern.
Schema Evolution:
Handling changes to data schemas over time can be tricky. A flexible approach is required to accommodate evolving data structures without disrupting existing processes.
Data Lineage and Traceability:
Establishing and maintaining clear data lineage is crucial for understanding where data comes from and how it has been transformed. Lack of proper data lineage can lead to confusion and errors.
User Adoption and Training:
Users may struggle to adapt to new tools and methodologies associated with data lakes. Proper training and support are essential for ensuring effective utilization.
Choosing the Right Technologies:
Selecting the right combination of technologies for storage, processing, and analytics can be challenging. The rapidly evolving landscape of data lake technologies adds to the complexity.
Performance Tuning:
Optimizing query performance in a data lake environment can be complex, especially as the volume and variety of data increase. This involves partitioning, indexing, and caching strategies.
Maintaining Data Consistency:
Ensuring consistency across various data sources and preventing data silos can be a challenge. Lack of consistency can lead to conflicting information and reduced trust in the data.
Monitoring and Logging:
Implementing effective monitoring and logging mechanisms is crucial for identifying issues, tracking changes, and ensuring the overall health of the data lake.
Addressing these challenges requires a combination of careful planning, ongoing management, and the use of appropriate technologies and best practices. Regular assessments and adjustments are often necessary to keep a data lake implementation running smoothly.
Conclusion
In conclusion, A data lake serves as a powerful and flexible solution for managing and analyzing vast amounts of diverse data. Its ability to store both structured and unstructured data in its raw form provides organizations with a comprehensive and scalable platform for deriving valuable insights. However, the successful implementation and utilization of a data lake come with their own set of challenges that need to be carefully addressed.
The journey of establishing and maintaining a data lake involves overcoming hurdles related to data quality, governance, security, and scalability.






