How to use pyspark in aws glue



Once upon a time, in a magical kingdom of Python, there were three special friends named Tuppy the Tuple, Setty the Set, and Dicky the Dictionary. Each of these friends had their own unique way of organizing and keeping things. Tuppy the Tuple Tuppy was like a magical box that could hold a list of…

In this article, we shall discuss about loc and iloc using the library pandas in python. First of all, let us learn what is pandas in python. WHAT IS PANDAS? Python pandas library has excellent functions to perform different tasks. The pandas library’s main objective is to select rows and columns from a dataset according…

In this Article we talk about Implementation of D-Tale using practical examples with code Before we begin to learn about D-Tale Automated Library, we’ll go over to learn what EDA is?, Objectives ( How it is performed ), How the EDA performed with python, Different Libraries in python for the purpose of performing EDA What…

Story: The Magic Toy Box Once upon a time, in a magical land, there was a little girl named Lily. Lily had a special toy box. But this wasn’t an ordinary toy box; it was a magic toy box! In this box, Lily could keep all her favorite toys and find them easily whenever she…

Data Visualization Data visualization is the graphical representation of information and data. By using visual elements like graphs, charts and maps. Data visualization tools provide an accessible way to see and understand trends, outliers and pattern in data. Data visualization draws on the theory of visual perception and cognition to present data in graphical forms…

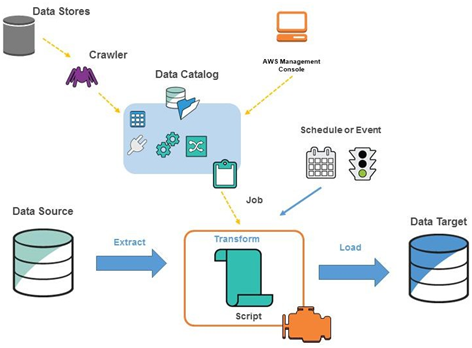
Introduction A data lake is a centralized repository designed to store, process, and secure large amounts of structured, semistructured, and unstructured data. It can store data in its native format and process any variety of it, ignoring size limits. A data lake provides a scalable and secure platform that allows enterprises to: ingest any data…